
Past couple of months I have been working on a Question Answering System and in my upcoming blog posts, I would like to share some things I learnt in the whole process. I haven’t reached to a satisfactory accuracy with the answers fetched by the system, but it is work in progress. Adam QAS on Github.
In this post, we are specifically going to focus on the Question Classification part. The goal is to classify a given input question into predefined categories. This classification will help us in Query Construction / Modelling phases.
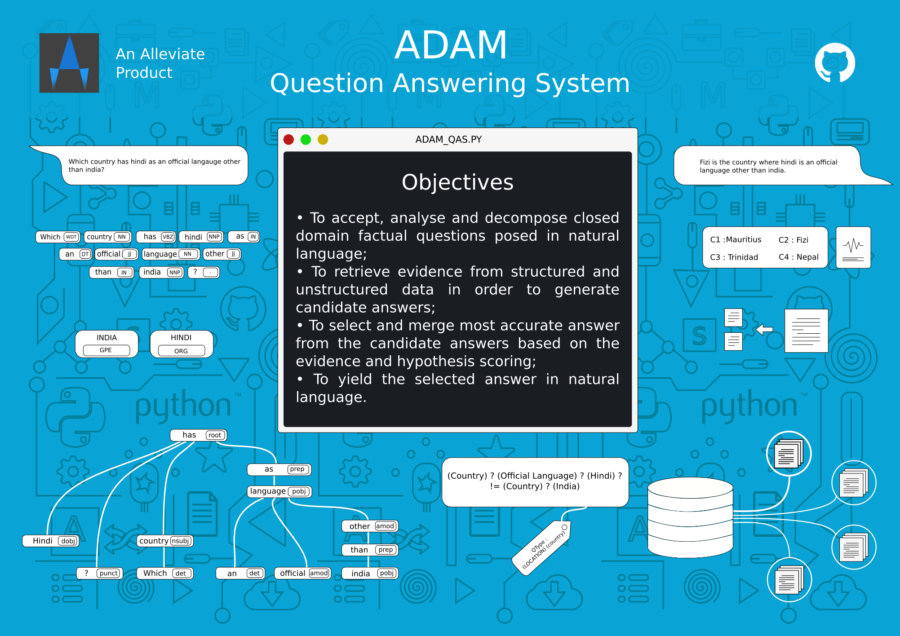
So, before we begin let’s make sure our environment is all set up. Setting up Natural Language Processing Environment with Python. For Question’s language processing part, we are going to use spaCy and for the machine learning part, we will use scikit-learn and for the Data Frames, I prefer pandas. Note: I am using Python3
$ pip3 install -U scikit-learn
$ pip3 install pandasNow, that our environment is all set we need a training data set to train our classifier. I am using the dataset from the Cognitive Computation Group at the Department of Computer Science, University of Illinois at Urbana-Champaign. ( Training set 5(5500 labeled questions, For more visit here.)
DESC:manner How did serfdom develop in and then leave Russia ? ENTY:cremat What films featured the character Popeye Doyle ? DESC:manner How can I find a list of celebrities ' real names ? ...
Prep Training data for the SVM
For this classifier, we will be using a Linear Support Vector Machine. Now let us identify the features in the question which will affect its classification and train our classifier based on these features.
- WH-word: The WH-word in a question holds a lot of information about the intent of the question and what basically it is trying to seek. (What, When, How, Where and so on)
- WH-word POS: The part of speech of the WH-word (wh-determiner, wh-pronoun, wh-adverb)
- POS of the word next to WH-word: The part of speech of the word adjacent to WH-word or the word at 1st position in the bigram (0th being the WH-word).
- Root POS: The part of speech of the word at the root of the dependency parse tree.
Note: We will be extracting the WH-Bigram also (just for reference); A bigram is nothing but two consecutive words, in this case, we will consider the WH-word and the word that follows it. (What is, How many, Where do…)
We have to extract these features from our labelled dataset and store them in a CSV file with the respective label. This is where spaCy comes in action. It will enable us to get the Part of Speech, Dependency relation of each token in the question.
import spacy
import csv
clean_old_data()
en_nlp = spacy.load("en_core_web_md")
First, we load the English language model and clean our CSV file from old training data. And then we read our raw labelled data, extract the features for each question, store these features and labels in a CSV file.
read_input_file(fp, en_nlp)
This function splits the raw data into the question and its respective label and passes it on for further NLP processing.
def process_question(question, qclass, en_nlp):
en_doc = en_nlp(u'' + question)
sent_list = list(en_doc.sents)
sent = sent_list[0]
wh_bi_gram = []
root_token = ""
wh_pos = ""
wh_nbor_pos = ""
wh_word = ""
for token in sent:
if token.tag_ == "WDT" or token.tag_ == "WP" or token.tag_ == "WP$" or token.tag_ == "WRB":
wh_pos = token.tag_
wh_word = token.text
wh_bi_gram.append(token.text)
wh_bi_gram.append(str(en_doc[token.i + 1]))
wh_nbor_pos = en_doc[token.i + 1].tag_
if token.dep_ == "ROOT":
root_token = token.tag_
write_each_record_to_csv(wh_pos, wh_word, wh_bi_gram, wh_nbor_pos, root_token)
The above function feeds the question into the NLP pipeline en_doc = en_nlp(u'' + question) and obtains a Doc object containing linguistic annotations of the question. This Doc also performs sentence boundary detection/segmentation and we have to obtain the list of sentences which acts as the decomposed questions or sub questions. (Here I am only operating on the first sub question). Let us iterate over each token in the sentence to get its Parts of Speech and Dependency label. To extract only the WH-word we have to look for WDT, WP, WP$, WRB tags and to extract the root token from the sentence we look for its dependency label as ROOT. After writing all the records to the training data CSV file, it looks something like this:
#Question|WH|WH-Bigram|WH-POS|WH-NBOR-POS|Root-POS|Class
How did serfdom develop in and then leave Russia ?|How|How did|WRB|VBD|VB|DESC
What films featured the character Popeye Doyle ?|What|What films|WP|NNS|VBD|ENTY
...
Training the SVM and Prediction
from sklearn.svm import LinearSVC
import pandas
I prefer pandas over sklearn.datasets, First thing is we load our training dataset CSV file in the pandas DataFrame. This data frame will have all the features extracted in column-row fashion. Now to train our classifier we need to separate the features column and the class/label column so, we pop the label column from the data frame and store it separately. Along with that, we will also pop some unnecessary columns.
y = dta.pop('Class')
dta.pop('#Question')
dta.pop('WH-Bigram')
X_train = pandas.get_dummies(dta)
Here, the get_dummies() function converts the actual values into dummy values or binary values. What this means is that, if a record is something like below it will be converted to its binary form with 1 being the feature is present in the record and 0 as being absent.
...
5. How|WRB|VBD|VB
...
# Why How What When Where ... WRB WDT ... VBD VB VBN VBP ...
...
5. 0 1 0 0 0 ... 1 0 ... 1 1 0 0 ...
...
In the next phase, we extract the same features from the question we want to predict in a data frame and get its dummy values. Here is the data frame get_question_predict_features() will return:
qdata_frame = [{'WH':wh_word, 'WH-POS':wh_pos, 'WH-NBOR-POS':wh_nbor_pos, 'Root-POS':root_token}]
en_doc = en_nlp(u'' + question_to_predict)
question_data = get_question_predict_features(en_doc)
X_predict = pandas.get_dummies(question_data)
The problem here is that the size (number of features) of prediction data frame and the training data frame varies due to the absense of some features in the prediction data frame. It is obvious that the question to be classified will be missing a majority of features that are present in the training dataset of 5000 questions. So, to equate the size (number of features) we append the missing feature columns that are present in the training data frame to the prediction data frame with the value of 0 (because these features are not present in the question to classify).
def transform_data_matrix(X_train, X_predict):
X_train_columns = list(X_train.columns)
X_predict_columns = list(X_predict.columns)
X_trans_columns = list(set(X_train_columns + X_predict_columns))
# print(X_trans_columns, len(X_trans_columns))
trans_data_train = {}
for col in X_trans_columns:
if col not in X_train:
trans_data_train[col] = [0 for i in range(len(X_train.index))]
else:
trans_data_train[col] = list(X_train[col])
XT_train = pandas.DataFrame(trans_data_train)
XT_train = csr_matrix(XT_train)
trans_data_predict = {}
for col in X_trans_columns:
if col not in X_predict:
trans_data_predict[col] = 0
else:
trans_data_predict[col] = list(X_predict[col]) # KeyError
XT_predict = pandas.DataFrame(trans_data_predict)
XT_predict = csr_matrix(XT_predict)
return XT_train, XT_predict
X_train, X_predict = transform_data_matrix(X_train, X_predict)
After we have both the data frames with the same size, we classify the question based on the training dataset using Linear Support Vector Machine. The LinearSVC model is fitted with the training features and respective labels. This fitted object is later used to predict the class with respect to the prediction data. It returns the question class/category.
Note: Here the DataFrame has multiple zero entries, hence you convert it into a sparse matrix representation; csr_matrix() takes care of that. from scipy.sparse import csr_matrix
print("Question Class:", support_vector_machine(X_train, y, X_predict))
def support_vector_machine(X_train, y, X_predict):
lin_clf = LinearSVC()
lin_clf.fit(X_train, y)
prediction = lin_clf.predict(X_predict)
return prediction
You can also experiment with a Bayesian Classifier (Refer: Naive Bayes Classifier in Python):
def naive_bayes_classifier(X_train, y, X_predict):
gnb = GaussianNB()
gnb.fit(X_train, y)
prediction = gnb.predict(X_predict)
return prediction
Fork it on GitHub:

Reference:
- Zhiheng Huang, Marcus Thint, Zengchang Qin. 2008. “Question Classification using Head Words and their Hypernyms“. Read Here.
- Why Natural Language Processing can be hard?
- Dependency Parsing in NLP
- Shirish Kadam, Amit Gunjal. 2017. “A Cognitive approach in Question Answering System“

Leave a Comment: