
In this blog post, I will be discussing all the tools of Natural Language Processing pertaining to Linux environment, although most of them would also apply to Windows and Mac. So, let’s get started with some prerequisites.
We will use Python’s Pip package installer in order to install various python modules.
$ sudo apt install python-pip $ pip install -U pip $ pip install --upgrade pip
So I am going to talk about three NLP tools in Python that I have worked with so far.
Note: It is highly recommended to install these modules in a Virtual Environment. Here is how you do that : Common Python Tools: Using virtualenv, Installing with Pip, and Managing Packages.
NLTK can be seen as a library written for educational purposes and hence, is great to experiment with as its website itself notes this; NLTK has been called “a wonderful tool for teaching, and working in, computational linguistics using Python,” and “an amazing library to play with natural language.” To install NLTK we use pip :
$ sudo pip install -U nltk
NLTK also comes with its own corpora and can be downloaded as follows:
>>> import nltk >>> nltk.download()

We can also interface NLTK with our own corpora. For detailed usage of the NLTK API usage, one can refer its official guide “Natural Language Processing with Python by Steven Bird”. I will be covering more about NLTK its API usage in the upcoming posts, but for now, we will settle with its installation.
spaCy :
In the words of Matthew Honnibal (author of spaCy);
” There’s a real philosophical difference between spaCy and NLTK. spaCy is written to help you get things done. It’s minimal and opinionated. We want to provide you with exactly one way to do it — the right way. In contrast, NLTK was created to support education. Most of what’s there is for demo purposes, to help students explore ideas. spaCy provides very fast and accurate syntactic analysis (the fastest of any library released), and also offers named entity recognition and ready access to word vectors. You can use the default word vectors, or replace them with any you have.What really sets it apart, though, is the API. spaCy is the only library that has all of these features together, and allows you to easily hop between these levels of representation. Here’s an example of how that helps. Tutorial: Search Reddit for comments about Google doing something . spaCy also ensures that the annotations are always aligned to the original string, so you can easily print mark-up: Tutorial: Mark all adverbs, particularly for verbs of speech . “
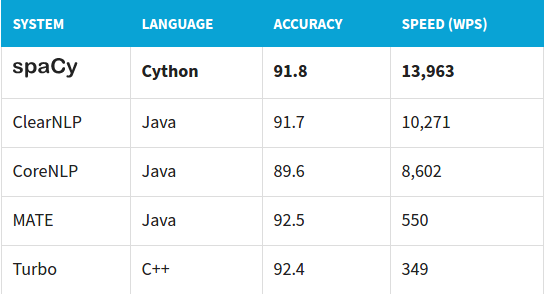
The benchmarks provided on its official website:
Here are some of the things I have tried with spaCy and it’s my favorite NLP tool. In the upcoming posts I will dwell into each of its APIs so, keep an eye out here (spaCy):
Installation :
$ sudo pip install -U spacy $ sudo python -m spacy.en.download
What makes it easy to work with spaCy is it’s well maintained and presented documentation. They also have made some great demos like displaCy for dependency parser and named entity recognizer. Check them out here.
TextBlob :
It is more of a text processing library than an NLP library. It is simple and light weight and is your go-to library when you have to perform some basic NLP operations such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
Installation :
$ sudo pip install -U textblob $ sudo python -m textblob.download_corpora
Usage to check word definitions and synonyms and similarity between different words. I will be doing an independent post on TexBlob with WordNet and its SynSets: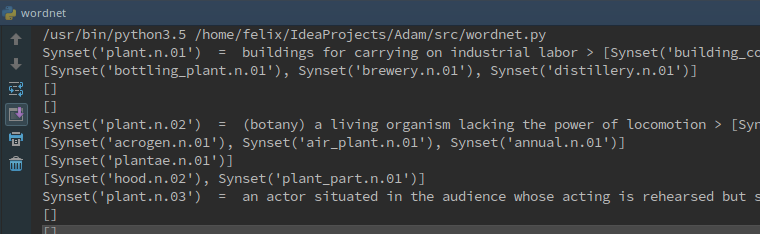
Check out my other posts on Natural Language Processing.
Further Reading :
- NLTK vs. spaCy: Natural Language Processing in Python.
- Java or Python for Natural Language Processing (Stack Overflow)
- Tutorial: What is WordNet? A Conceptual Introduction Using Python
- NLP library comparisons.
- Intro to NLP with spaCy
If you have any problem with installations or some other comments let me know below in the comments section. Meanwhile, you can also check out my other post on Machine Learning Classification algorithm. Naive Bayes Classifier in Python

Leave a Comment: